这是一个基于混合专家(MoE)和多头潜在注意力(MLA)架构的开源大语言模型,在数学推理、代码生成等复杂任务中表现优秀。该模型总规模达 671B 参数,但每个 token 只激活其中的 37B 参数。即在处理输入时,并非所有“专家”都参与计算,而是选择一部分专家进行处理。通过激活部分参数(37B)完成计算,从而降低了训练和推理的成本。...详情>>
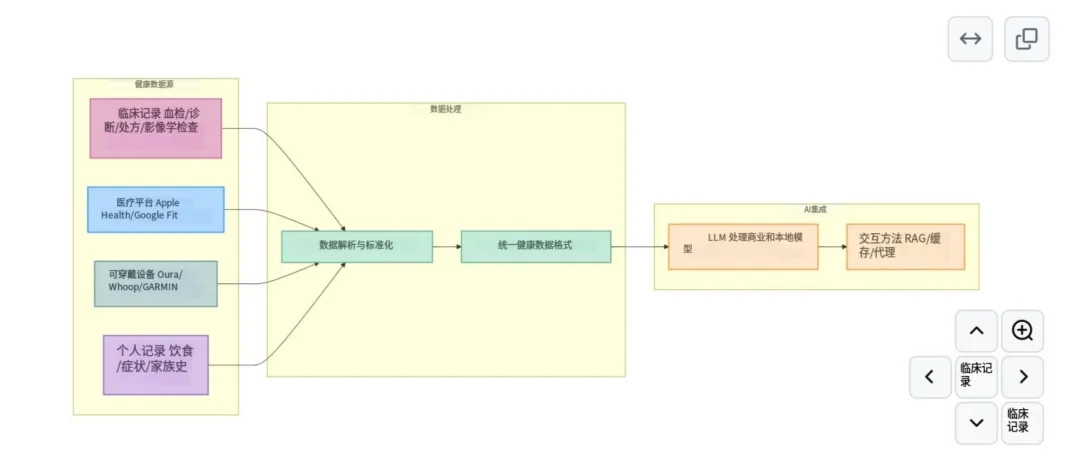
AI医疗是一个比较火的方向。年前给一家医院做过一次AI医疗的咨询。主要需求还是AI问诊,至于那些AI制药、A
超图软件近日在其互动平台上宣布,公司已成功完成对 DeepSeek-V3和 R1系列大模型的对接与适配。这一
华为官方今天宣布,DeepSeek V3/R1 671B旗舰模型(满血版)已基于华为云昇腾云服务全栈优化适配
华为官方今天宣布,DeepSeek V3/R1 671B旗舰模型(满血版)已基于华为云昇腾云服务全栈优化适配,可获得持平全球高端GPU部署模型的效果,满足业务商用部署需求。华为云昇腾云服务可以提供澎湃
DeepSeek 此前面向开发者推出 API 服务并提供 45 天的限时优惠价格,该优惠价格为每百万输入 tokens 在缓存命中的情况下 0.1 元、缓存未命中的情况下 1 元,而每百万输出 tok
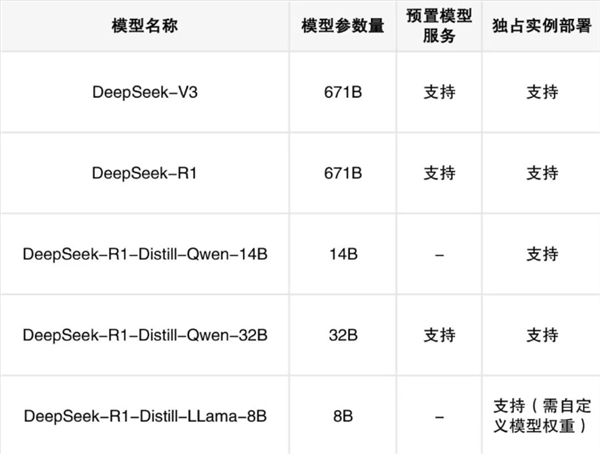
阿里云官方宣布,阿里云百炼平台已经全面上线DeepSeek全系列大模型,包括DeepSeek-V3、DeepSeek-R1、DeepSeek-R1-Distill-Qwen-32B/14B/7B/1.